

TrillionG the latest computer model developed by two engineers of DGIST, Himchan Park and Min-Soo Kim. TrillionG can generate synthetic data for simulating real world applications that use huge graphs. TrillionG is much faster than all existing synthetic graph generators. It requires very less memory and bandwidth. Let’s carry out a detailed study about the Google indexing techniques and how TrillionG makes Google Indexing easier.
Crawling the web
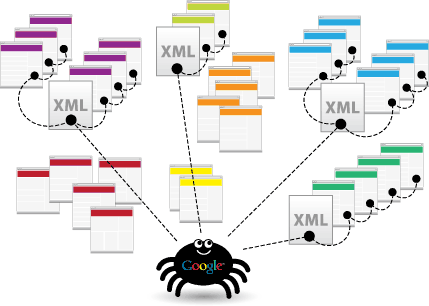
Have you ever wondered how Google brings us the most relevant result for our search queries from billions of websites? Google uses the web crawler software’s which works exactly as we search on Google. Crawling means following your links. Crawler will look for publicly available webpages and follow the links from the page. It will go through the links and store the data on Google’s server.
The working of the software is based on links. It will crawl webpages based on past crawling history or sitemaps provided by website developers. This is one reason why we create site maps, as they contain all the links in our blog and Google’s bots can use them to look deeply into a website. It will make the crawlers easily find the internal links from your site. The software will always look for newly created websites, modifying existing websites and specially for dead links. The software itself will determine the websites or pages to be crawled and how often it should fetch the pages.
You might hear about the Google Webmaster Tools. It is now known as Google Search Console. This is free and helps to know about the issues of your website such as malware attack, search indexing issues etc. Using this tool site owners can manage the crawling of their sites. They can request for a recrawl or manage them using “robots.txt”.
Robots.txt is a text file that resides in the root of your website. Bots are software’s used for website crawling. The bots crawl your site based on what you have written inside the robots.txt file.
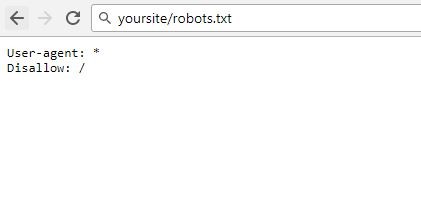
Factors which affects Google Crawling:
- Domain name that includes the main keyword are given importance.
- The more backlinks you have, the more you will get noticed by Google.
- Using Internal Links will help in deep crawling over the site.
- Use of xml sitemap or custom sitemap.
- Do not use duplicate content
- Use of unique meta tags
More about Google Webmaster Tools
Google Webmaster Tool is a highly recommended solution for your website search engine optimization. It can be used to analyze your website statistics frequently. It gives you all the information about how your website is indexed in Google and all.
Please find the major features of Google Webmaster Tool below:
- It checks your website sitemap.
- Adjust the crawl rate.
- Check the robots.txt file.
- List out the inbound and outbound links.
- Identify the keyword of the site and analyse the statistics.
- Check statistics about how Google has indexed your website and check for the issues.
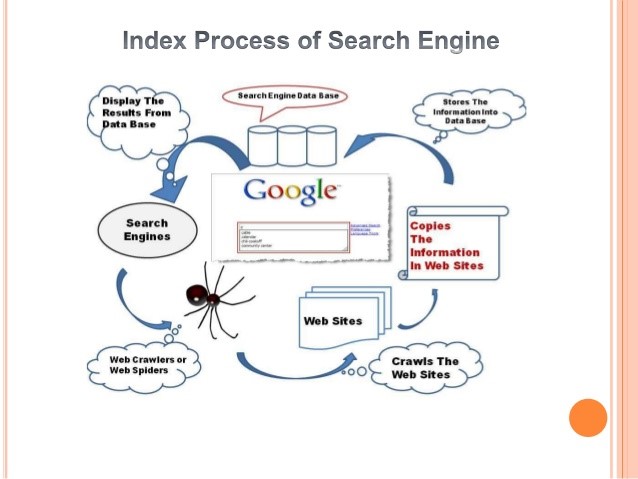
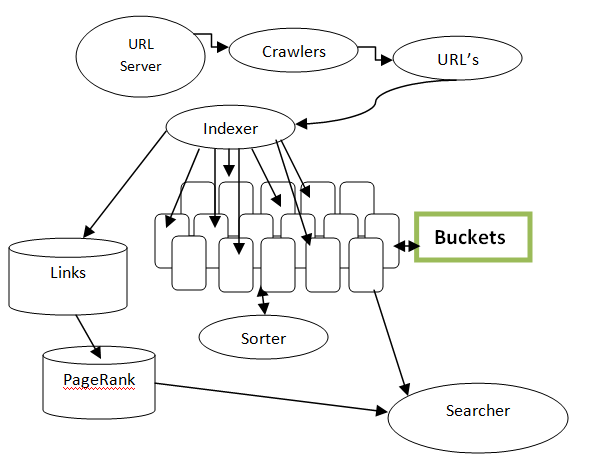
Search Engine Indexing
Search Engine Indexing involves collecting, parsing and storing of data. It is same as the index of a book. The genuine web crawler file is where every information the web crawler has gathered is put away. It is the web crawler file that gives outcomes to search, and pages that are put away inside the web search tool file that shows up on the web crawler.
When crawler finds a page, it will look for the keywords in it and keep a track of it in the Search index. The Google Search index contains hundreds of billions of web pages and is well over 10,00,00,000 gigabytes in size. When Google indexes a web page, it will add up to the entries.
Different type of data structures are available for the search index. These structures make the index more structured and helps in quick delivery of data.
- Tree – The ordered tree structure will have an associative array where keys are strings.
- Suffix tree – Supports linear time lookup and is structured like a Tree.
- Inverted index – Stores a list of occurrences in the form of a hash table or a binary tree.
- Citation index – Stores citations or links between certain documents to support citation analysis.
- Ngram index – Stores sequences of length of data, which supports other types of retrieval. Sometimes supports text mini too.
- Term document matrix – This is used in latent semantic analysis. A term document matrix stores the occurrences of words in documents in a two-dimensional sparse matrix.
Search Algorithm
Search algorithm will sort out the billions of webpages and give you the most relevant result within seconds. Google Search Algorithm will use the following techniques:
- Analyze what the words in your search query mean.
- Look for webpages with information that matches your query.
- Rank useful pages in the order based on the query.
- It uses Information such as your location, search history and Search settings to give you the apt result.
- Evaluate the result before delivering to us.
More interesting fact about Google’s Search Algorithm is that each year Google changes the algorithm around 500 to 600 times. The major algorithm updates are done occasionally.
Have you heard about Google Panda, Penguin and Hummingbird?
Google applies different names to its algorithm. Google Panda refers to quality of content, Penguin refers to quality of links and Hummingbird refers to the conversational search queries.

Based on Google panda algorithm only sites with high quality content will be listed on top of search results. Previously the panda update date was available for the public but now it is hard to understand whether the site SEO is affected by panda or not. The only way to prevent Panda attack is making your website rich with high quality content.
Website having low quality links will be discarded by Penguin algorithm. Penguin will consider only inbound links not outbound links. If your site is negatively impacted by Penguin then you need to make a link check and remove those low quality, spammy links from site. The happy news for website owners is that Google is supposed to release a new version of Penguin that will be Realtime.
Hummingbird is a part of Google’s main search algorithm from the initial time itself. Hummingbird understands the search queries better in terms of conversational search. Hummingbird gives high ranking to sites having high quality content and it answers any of your queries.
Factors to be considered for page ranking
Page optimization factors:
- Identify the Keyword
The name meta tag is one of the most powerful relevancy signals for a search engine. The tag itself is meant to provide the correct description of the pages. Search engines like Google use it to display the main title of a search result consisting of a keyword in it. This will indicate search engine what to rank the web page for. Preferably, the keyword must be located on the beginning of the identify tag. Pages optimized will rank better than pages with keywords closer to the identify’ s tag.
- Use of Keyword in meta description tag
The importance of the meta description tag nowadays is regularly discussed in search engine optimization circles. it’s far even though nonetheless a relevancy signal. it’s also essential for gaining clicks from search effect pages. together with the keyword in it makes it extra applicable to a seek engine.
- Use of Keyword in H1 tag
H1 tag is yet every other relevance aspect, serving as a description of the pages content. Despite an ongoing discussion approximately its importance, it’s miles nevertheless an awesome exercise to encompass your keyword in a unique H1 tag on a page.
- Use keyword in the page content
Your page content should have the keyword in it. But stuffing the page with keyword will have negative impact. Using keyword inside content will increase the relevancy of the content with regards to the search query.
- Duplicate content
Not all elements can impact your rankings emphatically. Having comparable content crosswise over different pages of your site can really hurt your rankings. Abstain from copying content and compose unique content for each page.
- Canonical tag
Sometimes having two URLs with comparative content is unavoidable. One of the courses keeping this from turning into a copy content issue is by utilizing an authoritative tag on your site.
- Image Optimization
It’s not just content that can be improved on a page yet other media as well. Pictures, for example, can send the web index significance motions through their alt content, subtitle, and depiction for instance.
- Content Updates
Google calculation lean towards newly refreshed content. It doesn’t imply that you need to alter your pages constantly. I trust that for business pages Google perceives the way they are not as delicate as blog entries covering late occasions. It is savvy however to incorporate some procedure to refresh certain sorts of substance once at regular intervals or somewhere in the vicinity.
- Internal links
Interlinking pages on your site can pass their quality between them. It will increase the user activity on you site.
- Keyword in URL
Counting the Keyword in the URL slug (that is the bit that shows up after the “.com/”some portion of the URL) is said to send another pertinence flag to Google.

Website factors
- Sitemap : A sitemap seeks search engines to file all the pages on your site. It is the least complex and most proficient approach to reveal Google what pages your site incorporates.
- Google Search Console integration: Having your webpage checked at Google Webmasters Tools is said to help with your destinations ordering. Regardless of the possibility that is not the situation, the instrument gives important information you can use to streamline your site better.
Other Factors
- The number of domains linked to your site is one of the most important ranking factors.
- The number of connecting pages. There may be a few connections from a specific space to your site; their number is a positioning element as well. In any case, it is still better to have a bigger number of connections from singular spaces instead of from a solitary area.
- Domain authority of connecting page. Not all pages are equivalent. Connections to pages with higher area specialist will be a greater variable than those on low expert spaces. In this way, you should endeavor to fabricate joins from high area specialist sites.
- Link significance. Some SEOs trust that connections from pages identified with your pages content convey more importance for web indexes.
- Authority of connecting area. The expert of a space might be a positioning element as well. Hence, a connection from low expert page on a high specialist site will be worth increasingly that from a lower space expert one.
- Links from a landing page. Some SEOs trust that connections from a landing page of a connecting space convey more quality.
- Number of do follow versus nofollow links. Google authoritatively expressed that they don’t check nofollow joins (connect with rel=nofollow trait appended). In this way the quantity of your take after connections should influence your rankings as well.
- Contextual links. It is said that connections inside the content of the page are worth more than joins in a sidebar for example.
Supergraphs
In early 90’s search engines used text based ranking systems to deliver the best result based on the search query. This method had several disadvantages. The search engine will look over the occurrences of the keyword and sometimes the domain name itself may not have any connection with the text. So, the end user may not get the relevant result for their query. This issue has been resolved using graph based ranking system.
The entire web represented as a directed graph with each entry is known as a node and the relationship or connections between entries is known as edges. Google page rank algorithm uses the supergraphs to process the large amount data. It represents the webpages as nodes and edges as the links.

Facebook’s Apache Giraph graph processor is the best example for Supergraphs. Apache Giraph is an iterative graph processing system built for high scalability. Facebook uses graph that represent people as nodes and their relationship as edges.
To test the Supergraphs we need unrestricted availability of the data. But according to the privacy policy there are some restriction in accessing the real data. Synthetic data needs to be generated in this case. But the fact is that the synthetic data may not always have the same relation rules as that of real data. It requires use of supercomputers connected through high speed network and large amount data needs to be analyzed.
Let us go through the newly discovered TrillionG technology here. It is a new method of building the graph. The most attractive feature is that it requires less computational time and memory. The new model reuses information that is kept in an extremely compressed size and in a quick computer cache memory during graph creation, making it more proficient and successful than existing models.
When we compare TrillionG with the existing models it can generate more realistic synthetic data and larger graphs. It can generate similar sized Trillion Edge graphs in a short period with less computer resources.
Through extensive experiments, we have demonstrated that TrillionG outperforms the state-of-the-art graph generators by up to orders of magnitude,” write the researchers in their study published in the Proceedings of the 2017 ACM International Conference on Management of Data.
The group expects that TrillionG could create engineered charts the extent of the human brain connectome, which comprises of 100 trillion associations between neurons, utilizing 240 standard PCs. IT organizations and colleges could likewise utilize extensive scale manufactured charts as a fundamental device for creating and assessing new graph algorithms and systems.
Why Google is my favorite?
My own favored web search tool is Google. This is not extremely unique but rather the reason that I like Google is not because the same number of individuals say, but it discovers more precise outcomes than different search engines.
Interface of Yahoo & MSN is over-burdened. MSN gives you a full page requesting that you find a house, Shop for Flowers, read news, and so forth, in addition to an entire rundown of decisions the utilization of which will not be evident until the you click them. Google then again offers a straightforward interface.
Google’s page gives you just the essential decisions: Web, News, Froogle, Groups, Directory.
I realize that you can redo your decisions with My MSN and the same on Yahoo! with My Yahoo, however people who need to perform only the most well-known thing on the Internet which is simply the search will soon find that Google’s less complex approach is far superior as it is speedier and simple to learn by everybody.